11.06课堂作业:Double DQN算法改进
作业题目
题目:分析Double DQN算法的改进动机、核心思想、算法架构和伪代码实现。
1. 改进动机
1.1 传统DQN的问题
传统DQN算法在Q值估计中存在一个严重问题:高估偏差(Overestimation Bias)。这个问题的根本原因在于:
1. max操作的高估问题
DQN使用max操作来选择最大Q值:
由于噪声的存在,max操作会倾向于选择被高估的Q值,导致Q值估计偏高。
2. 目标网络与评估网络的耦合
传统DQN中,同一个网络既要负责选择动作,又要负责评估动作值,这会导致高估偏差的累积。
1.2 高估偏差的影响
学习不稳定
过高估计的Q值会影响策略的收敛
性能下降
错误的Q值估计导致次优策略
样本效率降低
需要更多训练样本来纠正偏差
2. Double DQN的改进方法
2.1 核心思想
Double DQN通过解耦动作选择和动作评估来解决高估偏差问题。它使用两个独立的角色:
评估网络(Online Network)
负责选择最优动作
目标网络(Target Network)
负责评估选定动作的Q值
2.2 数学公式对比
传统DQN的目标函数
同一个网络既选择又评估
Double DQN的目标函数
在线网络选择,目标网络评估
2.3 关键改进点
动作选择
使用在线网络选择最优动作:
Q值评估
使用目标网络评估选定动作的Q值:
3. Double DQN架构图
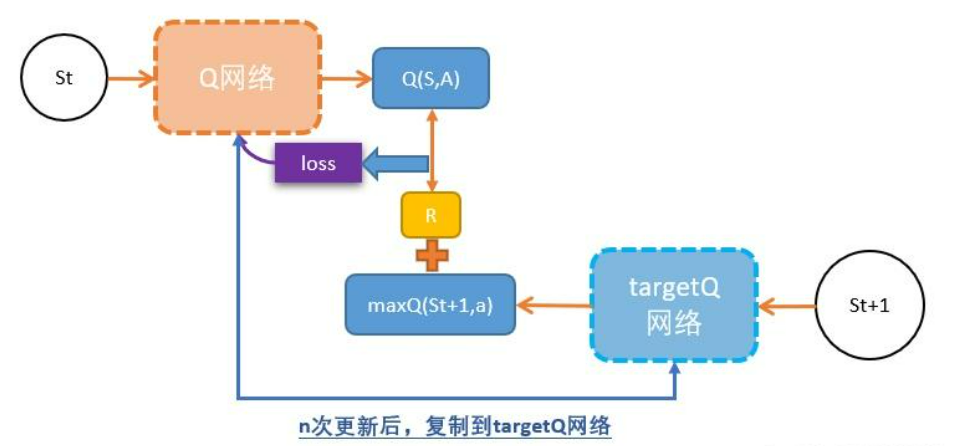
架构说明
Double DQN包含两个网络:
- 在线网络(Online Network):参数为 \(\theta\),用于选择动作
- 目标网络(Target Network):参数为 \(\theta^-\),用于评估Q值
目标网络定期从在线网络复制参数,保持相对稳定。
数据流程
经验回放池
\((s, a, r, s')\)在线网络
选择 \(a^* = \arg\max Q_{\text{online}}(s',a')\)目标网络
评估 \(Q_{\text{target}}(s',a^*)\)计算目标
\(y = r + \gamma Q_{\text{target}}(s',a^*)\)4. 算法伪代码
初始化在线网络参数 θ
初始化目标网络参数 θ⁻ ← θ
初始化经验回放缓冲区 D
for episode = 1 to M do
初始化状态 s₁
for t = 1 to T do
# 使用 ε-greedy 策略选择动作
if random() < ε:
a_t = 随机动作
else:
a_t = argmax_a Q_online(s_t, a; θ)
# 执行动作,观察结果
执行动作 a_t,观察奖励 r_t 和下一状态 s_{t+1}
# 存储经验
将转移 (s_t, a_t, r_t, s_{t+1}) 存入 D
# 从经验回放池采样
从 D 中随机采样小批量转移 (s_j, a_j, r_j, s_{j+1})
# Double DQN 关键步骤
# 步骤1:在线网络选择动作
a* = argmax_a Q_online(s_{j+1}, a; θ)
# 步骤2:目标网络评估Q值
y_j = r_j + γ * Q_target(s_{j+1}, a*; θ⁻)
# 计算损失
L(θ) = (y_j - Q_online(s_j, a_j; θ))²
# 通过梯度下降更新在线网络参数
θ ← θ - α∇_θ L(θ)
# 定期更新目标网络
if t mod C == 0:
θ⁻ ← θ
end
end算法关键步骤解析
动作选择(在线网络)
使用在线网络 \(Q_{\text{online}}\) 选择下一状态 \(s'\) 的最优动作:
这一步确定了我们认为最好的动作。
Q值评估(目标网络)
使用目标网络 \(Q_{\text{target}}\) 评估选定动作的Q值:
这一步避免了高估偏差,因为评估和选择是分离的。
损失计算
计算预测Q值与目标Q值之间的均方误差:
参数更新
通过梯度下降更新在线网络参数,目标网络定期从在线网络复制参数:
5. 总结
Double DQN通过对传统DQN的简单而有效的改进,成功解决了Q值高估偏差问题。其核心创新在于将动作选择和Q值评估分离到两个不同的网络中,这一改进虽然简单,却显著提升了算法的性能和稳定性。
关键优势
解决高估偏差
通过解耦动作选择和评估,有效减少Q值高估
实现简单
只需修改目标Q值的计算方式,代码改动很小
性能提升
在多个基准测试中表现优于传统DQN
训练稳定
减少Q值波动,提高学习稳定性